
This post is about how to upgrade an existing Scaleway Terraform deployment from Scaleway provider 1.16.0 to 2.0.0-rc1 … when you have some resources whose name is changing along the way …
The naïve approach
It was a saturday morning and I thought : “Hey, let’s do some changes in my Scaleway Kapsule Kubernetes cluster!”
You know, one of these days when you have a luminous idea … and then you try to apply it and you find yourself in troubles you never imagined … let’s get back to the idea.
I was thinking about tweaking some stuff like auto-upgrade feature and auto-healing of nodes … stuff like that. While looking at the Scaleway Terraform provider documentation, I remembered that I was still using version 1.16.0 in which some resources were still beta. So I decided to upgrade the version of my provider too … big mistake !
To complete the picture, I must specify that :
- The resources that must be renamed are:
scaleway_registry_namespace_betascaleway_k8s_pool_betascaleway_k8s_cluster_beta
- I’m using Terraform Cloud coupled to my Github repository to automate deployments
- I recently switched my development platform from a remote Linux machine to Ubuntu running in WSL2 on my Windows 10 workstation.
- I installed Terraform 0.14.6 in my Ubuntu WSL2 environment.
You start to see the issues coming, do you ? :)
So, I created a feature branch in my local git repository and started to adapt the version of the provider and the name of resources. Yeah, indeed, I did not have a look at the documentation of the provider to check if there were some special steps to consider … dumb me !
I pushed the new feature branch to my Github repo and created a pull request … then the first problem happened.
Problem 1 - resource name mismatch new provider versus current state file
The terraform plan (automatically executed in Terraform Cloud) failed because I had forgotten to also rename resource in my output.tf file. Ok, no big deal, I fixed this and added a new commit to the PR … Unfortunately, it still failed but this time with the following message :
Error: no schema available for scaleway_registry_namespace_beta.example while reading state;
this is a bug in Terraform and should be reported
Error: no schema available for scaleway_k8s_pool_beta.example while reading state;
this is a bug in Terraform and should be reported
Error: no schema available for scaleway_k8s_cluster_beta.example while reading state;
this is a bug in Terraform and should be reportedDamn, what’s this now … Then I tilted. Terraform reads the state file and checks if the content is in line with the .tf files that it has to apply. Of course there was no schema for those beta resources anymore because it was present in the old provider … but I’m using the new one …
So, I decided to read the documentation and obvisouly, there are some steps to take before upgrading the provider !
Fix 1
So I tried to collect all ids of the resources that are renamed.
# List resources in the Terraform state file
terraform state list
...
scaleway_k8s_cluster_beta.example
scaleway_k8s_pool_beta.example
scaleway_registry_namespace_beta.example
...
# Get id of each resource
terraform state show scaleway_k8s_cluster_beta.example
Error: Could not load plugin
Plugin reinitialization required. Please run "terraform init".
Plugins are external binaries that Terraform uses to access and manipulate
resources. The configuration provided requires plugins which can't be located,
don't satisfy the version constraints, or are otherwise incompatible.
Terraform automatically discovers provider requirements from your
configuration, including providers used in child modules. To see the
requirements and constraints, run "terraform providers".
Failed to instantiate provider "registry.terraform.io/scaleway/scaleway" to
obtain schema: unknown provider "registry.terraform.io/scaleway/scaleway"Ouch, another problem.
Problem 2 - Provider mismatch
Indeed, I was issuing the terraform command from my local WSL2 environment using the feature branch of my local git repository using the new provider. So I switched to my local main branch and ran a terraform init to get the Scaleway Terraform provider 1.16.0 again.
Fix 2
# Run terraform init to get back correct Scaleway provider version
terraform init
Initializing the backend...
Initializing provider plugins...
- Finding scaleway/scaleway versions matching "~> 1.16.0"...
- Installing scaleway/scaleway v1.16.0...
- Installed scaleway/scaleway v1.16.0 (signed by a HashiCorp partner, key ID F5BF26CADF6F9614)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
terraform state show scaleway_k8s_cluster_beta.example
# scaleway_k8s_cluster_beta.scw-k8s-seblab:
resource "scaleway_k8s_cluster_beta" "example" {
apiserver_url = "<redacted>"
cni = "<redacted>"
description = "<redacted>"
enable_dashboard = false
id = "fr-par/11111111-1111-1111-1111-111111111111"
ingress = "<redacted>"
kubeconfig = [
{
cluster_ca_certificate = "<redacted>"
config_file = <<-EOT
<redacted>
EOT
host = "<redacted>"
token = "<redacted>"
},
]
name = "<redacted>"
region = "fr-par"
status = "ready"
tags = []
upgrade_available = true
version = "1.20.1"
wildcard_dns = "<redacted>"
auto_upgrade {
enable = false
maintenance_window_day = "any"
maintenance_window_start_hour = 0
}
autoscaler_config {
balance_similar_node_groups = false
disable_scale_down = false
estimator = "binpacking"
expander = "random"
expendable_pods_priority_cutoff = 0
ignore_daemonsets_utilization = false
scale_down_delay_after_add = "10m"
scale_down_unneeded_time = "10m"
}
}All ids were collected, time to delete the resources from the state file.
Problem 3 - Terraform state mismatch
Remember that I use a new local WSL2 Ubuntu environment for my developments … then you guess what came next …
# Run terraform state rm <resource name> to delete the resources from the state file (hosted in Terraform Cloud)
terraform state rm scaleway_registry_namespace_beta.example
Error: Terraform version mismatch
The local Terraform version (0.14.6) does not match the configured version for
remote workspace <redacted> (0.13.5). If you're sure you want to upgrade
the state, you can force Terraform to continue using the
-ignore-remote-version flag. This may result in an unusable workspace.
Error loading the state: Error checking remote Terraform version
Please ensure that your Terraform state exists and that you've
configured it properly. You can use the "-state" flag to point
Terraform at another state file.Aaaaaargh !
Ok ok, let’s take a deep breath and cool down …
Fix 3
So, I downloaded the version 0.13.5 of the terraform binary inside my current directory and ran the ./terraform state rm using that version.
./terraform state rm scaleway_registry_namespace_beta.example
Removed scaleway_registry_namespace_beta.example
Successfully removed 1 resource instance(s).After the removal of all obsolete resources from the state file, I wanted to switch back to the feature branch of the git repository containing the new version of the provider and the new resource names and import the resources with their new name and current id (collected earlier).
Problem 4 - Missing Scaleway configuration
The terraform import command failed with the following error:
|
|
Oh well … new environment and using Terraform Cloud to apply my Terraform means no more Scaleway credentials.
Fix 4
Easy fix, I downloaded the Scaleway CLI and ran scw init to configure credentials. I could also have configured the credentials through environment variables.
Problem 5 - Provider versus resource mismatch (again)
The import failed with the following error :
./terraform import scaleway_registry_namespace.example fr-par/11111111-1111-1111-1111-111111111111
scaleway_registry_namespace.example: Importing from ID "fr-par/11111111-1111-1111-1111-111111111111"...
Error: unknown resource type: scaleway_registry_namespace
Releasing state lock. This may take a few moments...Ok, still using old provider, time to run terraform init again.
Fix 5
./terraform init
Initializing the backend...
Initializing provider plugins...
- Finding scaleway/scaleway versions matching "2.0.0-rc1"...
- Installing scaleway/scaleway v2.0.0-rc1...
- Installed scaleway/scaleway v2.0.0-rc1 (signed by a HashiCorp partner, key ID F5BF26CADF6F9614)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/plugins/signing.html
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
./terraform import scaleway_registry_namespace.example fr-par/11111111-1111-1111-1111-111111111111
scaleway_registry_namespace.example: Importing from ID "fr-par/11111111-1111-1111-1111-111111111111"...
scaleway_registry_namespace.example: Import prepared!
Prepared scaleway_registry_namespace for import
scaleway_registry_namespace.example: Refreshing state... [id=fr-par/11111111-1111-1111-1111-111111111111]
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.Yeepie ! Import fixed, I could import all needed resources.
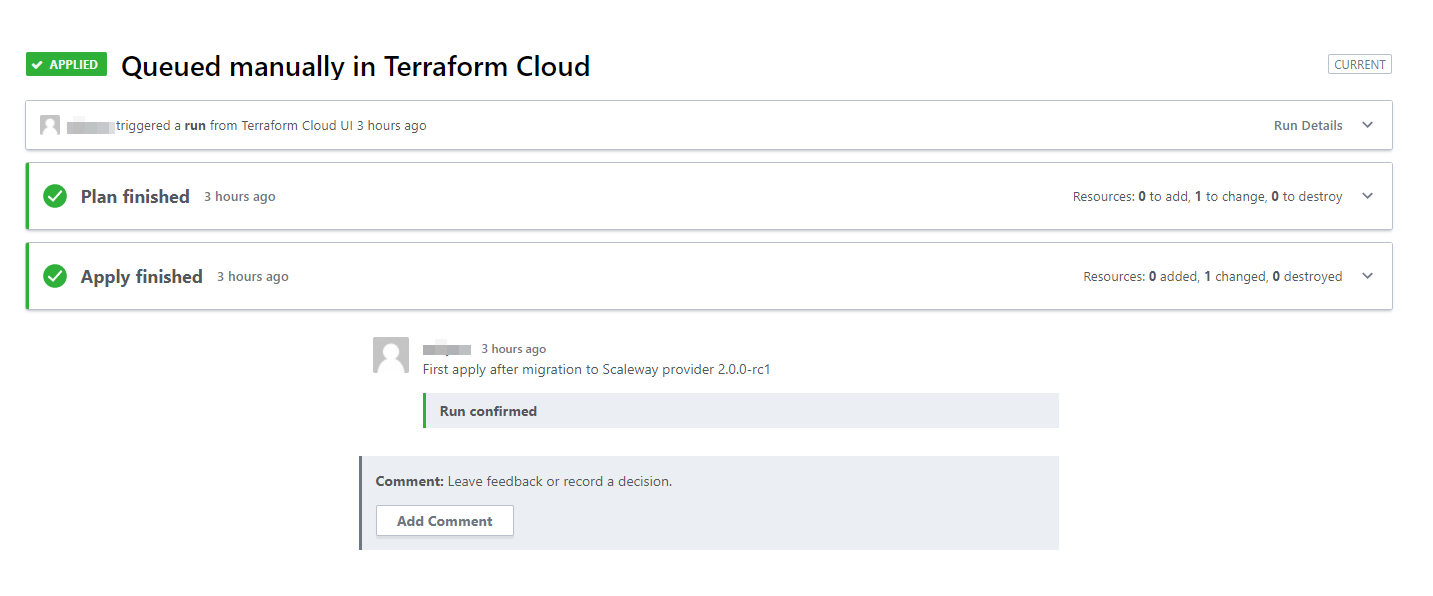
I then ran a terraform plan to check that nothing will break and that confirmed that only some new attributes of the Kapsule Kubernetes cluster were mentioned as candidate for in-place update.
Final step
The last action was to queue a terraform apply run in Terraform Cloud to confirm that everything was once again good to go …
Conclusion
Never start your saturday morning with a Terraform provider migration !